

告别头文件,编译效率提升 42%!C++ Modules 实战解析 | 干货推荐
模块相比传统文件有哪些优势?
编者按:Alibaba Cloud Linux (简称“Alinux”)是目前阿里云上占比第一的操作系统。2021 年,龙蜥以 Alinux 产品为基础发布了 Anolis OS 8 正式版。本文中,阿里云智能集团开发工程师李泽政以 Alinux 为操作环境,讲解模块相比传统头文件有哪些优势,并通过若干个例子,学习如何组织一个 C++ 模块工程并使用模块封装第三方库或是改造现有的项目。此外,还会介绍 Modules 在龙蜥社区理事长单位阿里云内部项目的应用。C++20 Modules 代码在 Alibaba Hologres 主线上已稳定运行一年半以上,并减少了 42% 的编译时间。
简介
模块(Modules) 是 C++20 的四大重要特性(Coroutines、Ranges、Concepts 以及 Modules)之一。它为 C++ 引入了模块的概念,允许用户通过“import”来导入模块,并通过模块来组织项目工程,从而大大提升编译速度,改善封装性。
Alibaba Cloud Compiler是阿里云编译器团队打造的C++编译器,基于 Clang/LLVM 社区开源版本开发,提供了良好的 Coroutine(协程)和 Modules(模块)支持,并将这些代码积极合入到上游社区,为 Clang 的 module 的支持做出了大量贡献。
Hello World!
头文件版本
我们先来看一个基本的对比,这是一个 C++ 的 hello world 代码。程序会简单的打印 Hello world。
#include <iostream>
int main() {
std::cout<<"Hello world!"<<std::endl;
}传统的头文件写法采用 #include 预处理器的语法:
1. 在编译之前,预处理器把整份 iostream 文件的内容复制粘贴到代码中。虽然上面的程序看上去很简单,但展开以后的代码可达到 3 万行,约 1MB!(libstdc++ 下测试)。如果我们想要包含整个标准库,展开以后的代码可达 10 万行以上,约 4MB。
2. 编译器需要对如此之多的代码完成词法语法语义分析,执行相应的优化,并生成最后的代码。
在debug 模式下,我们编译了一个类似的 demo 代码:
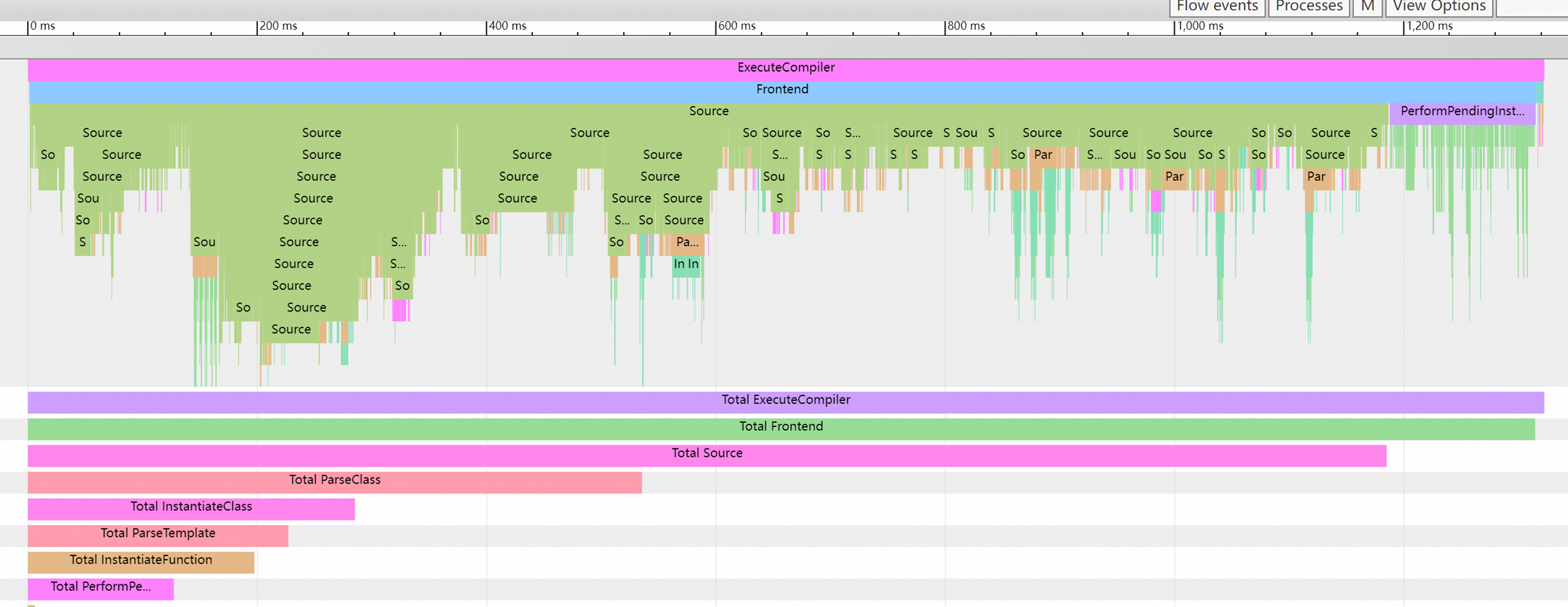
测量结果如上所示,耗时约 1.2s。
可以看到,在编译类似的 demo 代码时,需要在头文件上花费大量的时间,并且在这个例子中,几乎都耗在编译器前端(预处理,词法语法语义分析等工作上)。
模块版本
C++20 以后,我们可以使用模块语法来导入标准库。
import std;
int main() {
std::cout<<"Hello world!"<<std::endl;
}
可以看到,只需要 import std;就可以引入整个标准库,无需精确的包含对应的 iostream 功能模块。尽管我们导入了整个标准库,整个编译流程的速度依然非常快,这是因为头文件中的代码已经被预先编译好,导入模块时无需再次编译。

实测耗时约 0.03 秒左右,相比头文件编译速度提升了一个数量级以上。使用模块大大加速了编译时间,可以看到前端耗时的占比相对减小了很多,因为我们不需要预处理标准库中的内容,也不需要对它们做词法语法语义上的分析,只需要简单的反序列化已经编译好的模块产物即可。
头文件 VS 模块
C++ 的头文件有许多缺点,而模块针对这些缺点做出了重大的改进:
重复编译导致编译缓慢
头文件的重复编译
C++ 用户常常抱怨 C++ 编译速度慢,其中一个原因就来自于头文件的重复编译。
接下来我们简要介绍一下 C++ 的重复编译问题:
#include<string>
void split(std::string& str)
{
//...
}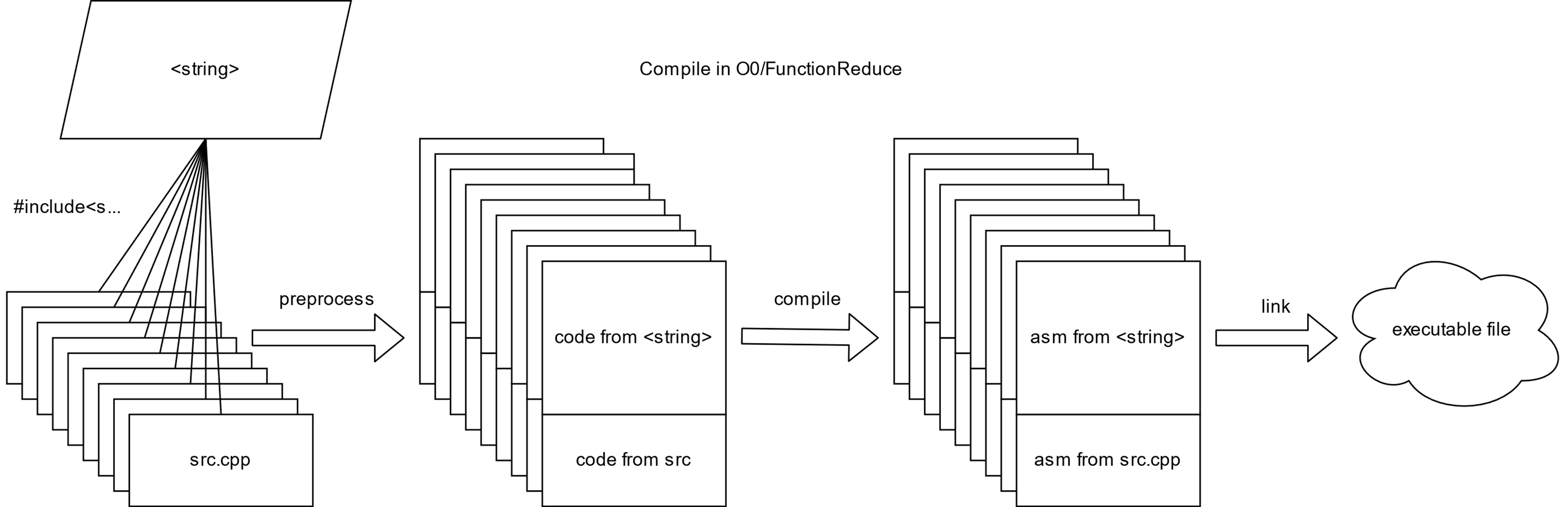
如上图所示:假如有 M 份类似于 src.cpp 的源代码,每份代码都包含了头文件 string,这在项目中是非常常见的。因此,在整个项目的构建过程中,我们不得不对这份代码做 M 次预处理和 M 次编译,生成 M 次 string 相关的汇编,这非常耗时。
不妨假设一个最坏情况:项目中有 N 个头文件和 M 份源代码,且每份源代码都包含了全部 N 个头文件,那么整个项目的编译时间复杂度就达到了 O(N*M)。这正是大型 C++ 工程构建缓慢的原因之一。
模块的编译提速
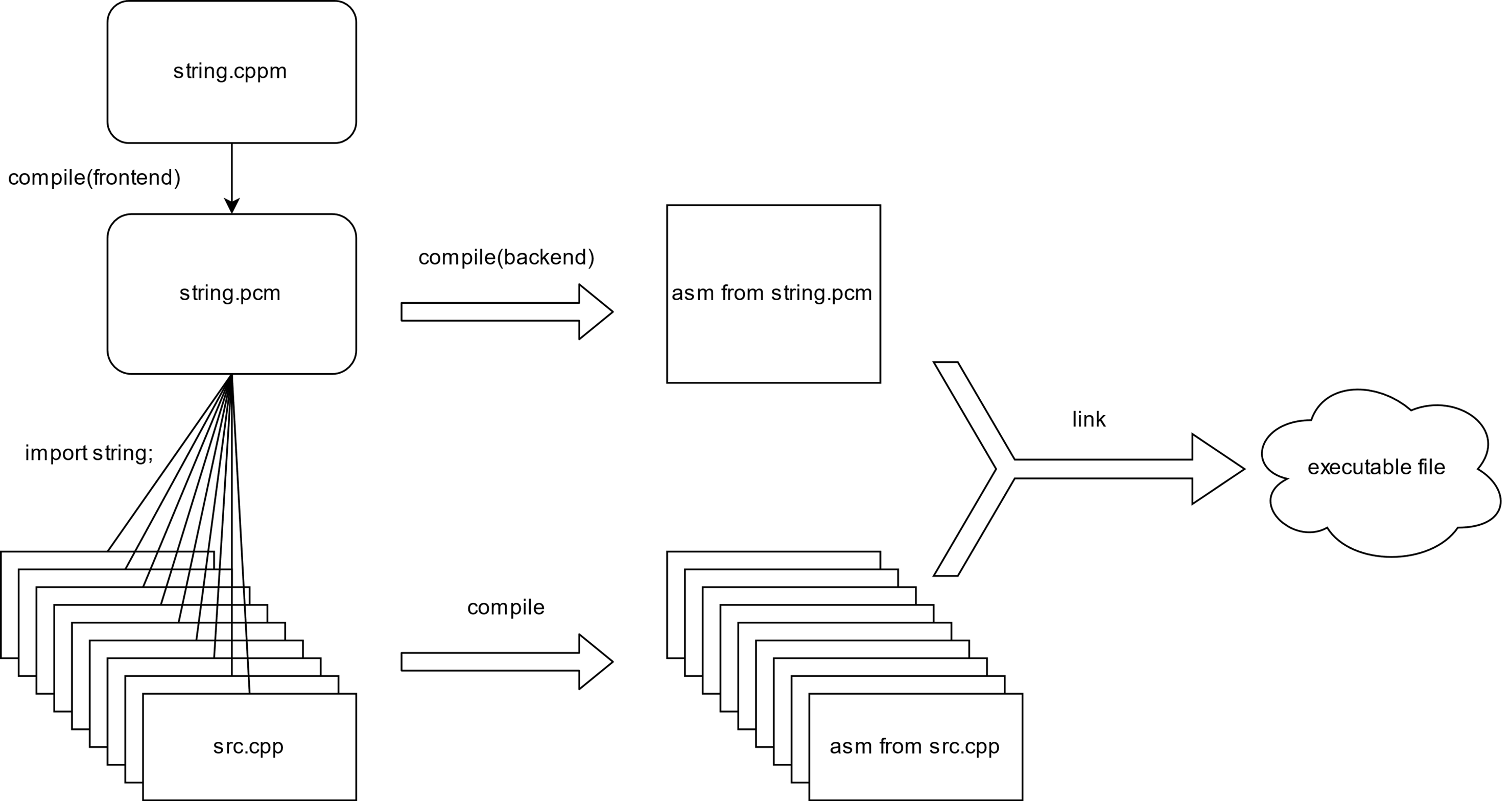
引入模块以后,我们可以看到,模块文件本身也是一个编译单元,会被单独编译处理,不会被预处理加入到每份源代码中重复编译。假如有 M 份源代码和 N 个模块,编译的时间复杂度仅为 O(N+M)。
缓慢的二次编译
之前我们讲述了一个编译整个项目的场景,并分析了这个场景下头文件缓慢的原因。另外一个常见的场景是程序员二次编译开发,修改少量代码然后再次编译(允许复用缓存),此时,模块依然具有显著的编译速度优势。
头文件不是代码单元,不能被独立编译
假如有以下代码:
#include <mylib.h>
int main() {
mylib::cout<<"Heloo!";
}当我们编写完成以后,才发现打错了字,把 Hello 拼错了。为此,我们需要修改字符串,然后重新编译。
#include <mylib.h>
int main() {
mylib::cout<<"Hello!";
}由于我们只修改了字符串的内容,从理想情况下推测,第二次编译应该比第一次编译快得多。这是因为二次编译应该能够利用之前编译好的结果,只需要重新编译 main 函数即可。
然而,由于头文件并不被视为一个可以独立编译的编译单元(源代码文件),因此编译器不会独立编译 mylib.h,导致我们不能复用第一次编译的结果,因此第二次编译的时间和第一次是差不多。
模块是可以被独立编译的代码单元
模块其本身可以被编译。上面的例子如果使用 import mylib; 代替头文件,那么二次编译的速度将会非常快,因为 mylib 本身是一个可以被独立编译的代码单元。当我们修改 main 函数并二次编译时,构建系统会发现 mylib 的内容没有改动,无需二次编译。
此时,我们只需要重新编译一个 main 函数即可,这就是模块的二次编译速度远快于头文件的根本原因。因为头文件不得不重新编译所有被 include 进来的代码,而模块则可以简单的复用上一次独立编译 mylib 的中间产物。
"卫生"与独立性
头文件不够“卫生”,被其他代码影响
头文件的另外一个缺点就是不够“卫生”,会被外部代码影响。
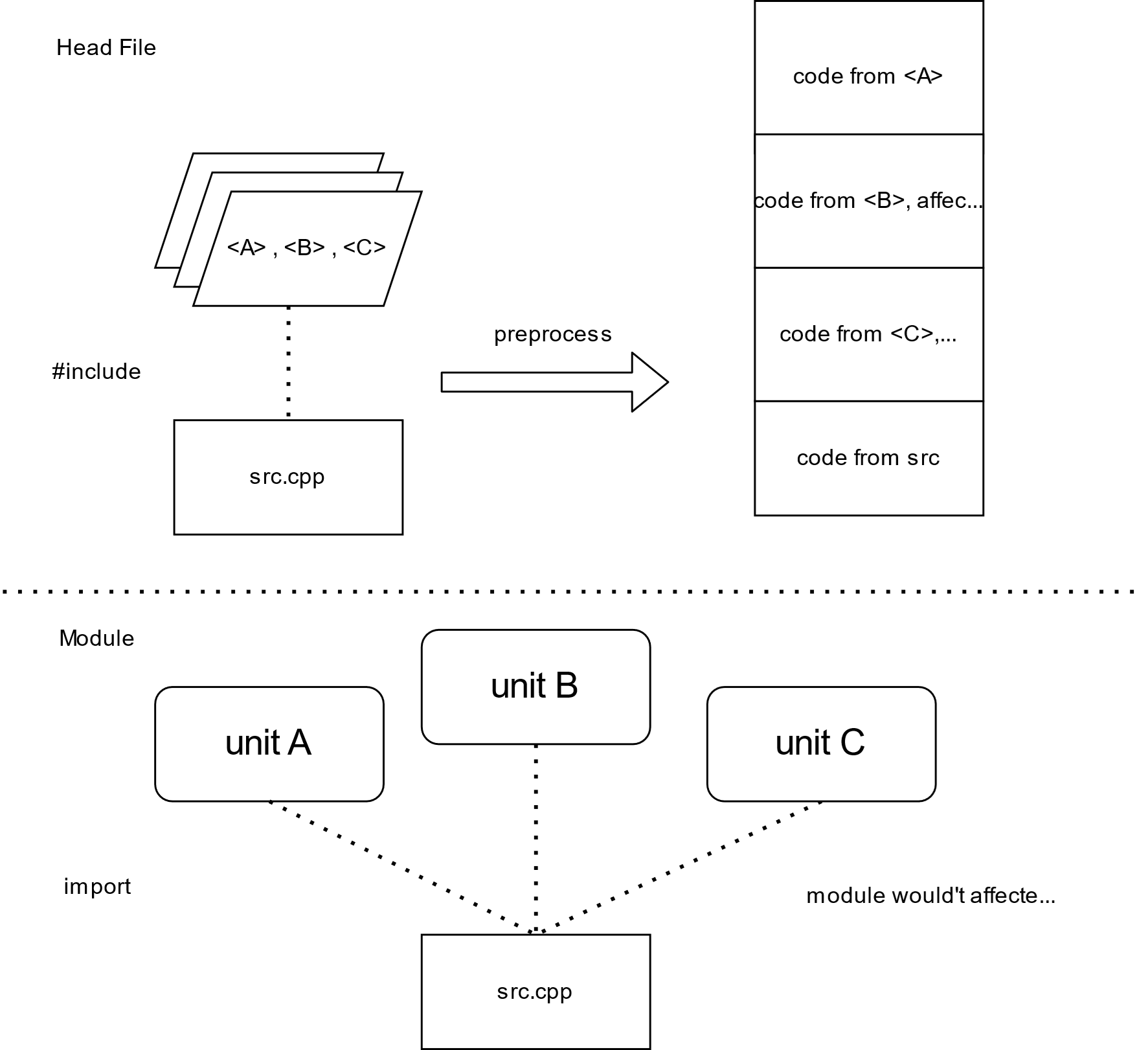
如上图所示,我们在 src.cpp 中按顺序 #include A,B,C 三个头文件,按照 #include 的顺序,由于 #include 仅仅只是复制粘贴,这导致了 B 中的内容会被 A 影响,C 的内容则可能会被 A 和 B 影响。
这导致了几点:
-
顺序依赖性:可能需要按特定顺序包含头文件,不然就会使用出错,从而加大了使用难度。
-
妨碍并行编译和预编译:由于被其他代码影响,ABC 不能并行编译,我们也难以独立的预编译头文件(因为只有被 include 以后我们才能确定头文件的上下文),这大大的限制了编译速度。
-
潜在的冲突可能:比如,头文件 A 中定义了一个宏,刚好 B 中用到了这个宏的名字,那么 B 的内容就会意外的被破坏。(典型如 windows 平台下的 max 宏干扰了 std::max 函数)
模块是"卫生"的:不受外部代码影响
模块不通过预处理方式机械的复制粘贴代码,而是将每一个模块都单独独立编译,从而保证模块内部的内容不受外部代码影响,因此模块是“卫生”的。
封装控制
头文件缺乏封装
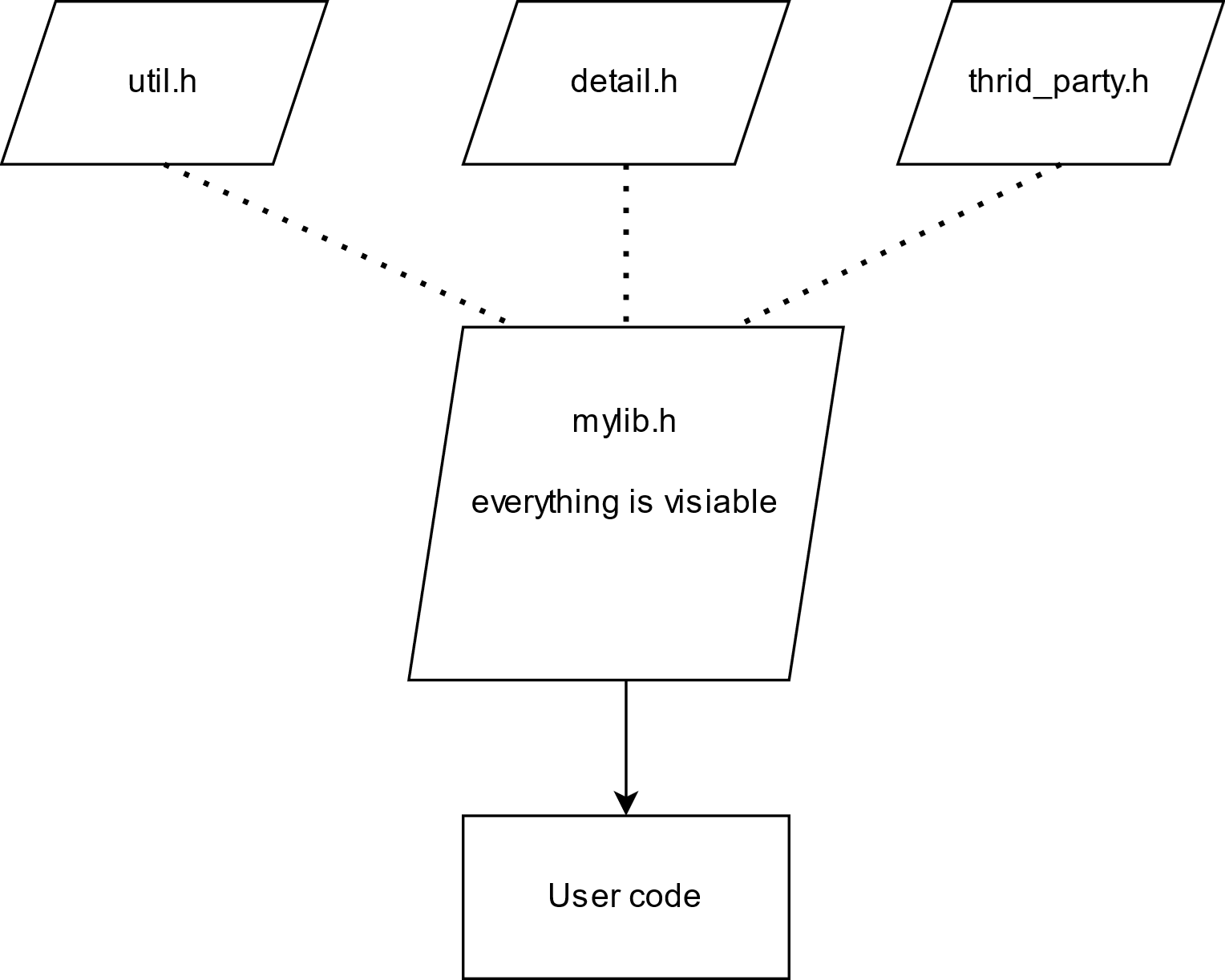
头文件还有一个重要的缺点,那就是头文件内部的所有的声明都会暴露给外部。比如,假如有一个 mylib 头文件,其内部包含了第三方库的头文件和一些内部实现细节,我们可能不想把这些细节暴露给用户。但是在头文件中,这些符号对用户都是可见的,我们无法控制哪些符号对外部用户可见。因此,它们可能会影响到用户的代码,用户也可能会错误的使用不打算对外暴露的接口。
模块具有良好的封装
在模块中,我们通过 export 关键字,标明哪些声明会被暴露给外部,如果没有标明 export 关键字,这些声明默认对外部是不可见的,这就解决了上述问题。
模块语法简介
本章节会简要的介绍模块新引入的若干声明语法,并通过样例介绍如何使用这些语法。
Export Declaration
export 控制可见性
模块回收了关键字 export,被 export 关键字修饰的声明会被导出给模块外部的外部代码使用。
未添加 export 关键字的声明,对外部用户是不可见的,外部用户无法使用该声明。
// Hello.cppm
export inline int a; // 导出一个变量
export void foo(); // 导出一个函数声明
void bar(); // 该声明未被导出
export void foo(){…} // 导出一个函数实现
export class A {}; // 导出一个类
export enum B {}; // 导出一个枚举
export namespace my_lib {}; // 导出一个名称空间
export template<typename T> C{}; // 导出模板
export using std::max; // 导出using declaration
export using D=std::vector<int>; // 导出别名
// main.cpp
import Hello;
int main() {
foo(); //使用模块中被导出的声明
// bar(); 编译错误!无法使用未被导出的声明!
}无法被 export 的情形
需要注意的是,有些东西无法被 export:
1. 宏:宏只存在于预处理阶段,因此一个模块无法导出一个宏。同样的,外部代码中的宏也不会影响模块内部中的代码。
2. using namespace 声明,比如 export using namespace std;,在头文件/模块中导出这类声明并不是一个好主意,很容易破坏外部代码的预期行为,C++ 模块干脆禁止导出这样的声明。(当然你依然可以不加 export 关键字直接使用,这种情况下不会影响到外部代码)
使用不可见的声明
有趣的是,如下图代码所示,某些情况下,我们可以匿名的间接使用未被 export 的不可见的声明:
// Hello.cppm
struct my_string {
//...
};
export my_string hello();
export void hi(const my_string&);
// main.cpp
import hello;
int main() {
// my_string str = hello(); 不能这样写!因为my_string是不可见的
auto str = hello(); // 然而,我们可以通过自动类型推导来匿名的使用不可见类型
hi(str);
}
Module Declaration
一个模块可以由多个模块单元(Unit)组成,每个模块单元对应了一份代码文件,文件通常会使用一个特殊的后缀名(cppm,ixx)。
在一个模块单元中,有且只有一个模块声明(Module Declaration),表示这个单元从属于哪一个模块。
module Foo; //声明一个名为Foo的模块
export module Foo.Bar; //声明一个名为Foo.Bar的模块
module Foo.Bar.Gua; //声明一个名为Foo.Bar.Gua的模块需要注意的是,模块名字中的 . 符号,在语言角度上没有任何特殊的语义,不保证 Foo.Bar 和Foo 之间有从属关系,需要依赖用户来自己组织管理。
接口单元与实现单元
根据 Module Declaration 的不同,我们可以将模块单元区分成:
1. 接口单元(interface unit),一个模块只能有一个接口单元,只能在这个单元中使用 export declaration 对外暴露接口。
2. 实现单元 (implementation unit),一个模块可以有多个实现单元,实现单元里不能使用 export declaration。例如下面的代码,一个接口单元对于了两个实现单元,我们可以将实现拆分到多个文件中
// Foo.cppm
export module Foo; // interface unit
// Foo_impl1.cpp
module Foo; // implementation unit
// Foo_impl2.cpp
module Foo; // implementation unit通常来说,在模块中,用户不需要像传统的头文件工程那样,将声明与实现分离开来。然而,依然存在一些特殊情况,例如,对于汇编,我们可能希望分离声明与实现,并通过构建工具在不同平台上选择不同的实现。
我们依然可以通过接口单元和实现单元来模拟传统 C++ 工程中声明与实现的分离:
// Interface.cppm
// Interface Unit
export module thread;
class thread_context;
void switch_in(thread_context* to);
void switch_out(thread_context* from);
// Impl.cpp
// Implementation Unit
module thread;
class thread_context;
{
//define something
}
void switch_in(thread_context* to)
{
//do something
}
void switch_out(thread_context* from)
{
//do something
}
例如上述代码,它模拟了一个线程上下文切换的情况。
模块的接口文件,声明了 thread_context 类,以及 switch_in 和 switch_out 函数。右边则是模块对应的实现单元,里面实现了 thread_context 类和函数的细节。
由于在不同平台上对应的实现细节可能不同,因此我们可以准备多份不同的实现单元,根据目标平台选择对应的实现单元来编译。
模块分区
我们可以将一个模块拆成多个分区,需要注意的是,分区不是一个独立的模块,它不能被单独使用。
export module Foo.Bar:part1; //声明属于Foo.Bar模块的一个分区(Partition)
export module Foo.bar:part1:part2; // 不合法!分区不能嵌套!
module Foo.Bar:part1; //分区也具有Interface Unit和Implement Unit的区别 Import Declaration
接下来我们介绍模块的 import 声明,我们可以通过它来导入其他的模块。
// main.cpp
import std; // 导入标准库模块
import foo; // 导入foo.bar模块
import foo.bar:part1; // 不合法!不能导入一个其他模块的分区模块
// foo.cppm
export import foo.bar; // 导入foo.bar模块, 并将其再导出给外部用户
import std; // 导入std模块, 但是不暴露给外部用户
// foo.bar.cppm
export import :part1; // 导入自己的分区模块part1,并暴露给外部用户模块代码的基本结构
在介绍完 Export Declaration,Module Decaration 和 Import Decaration 以后,我们终于可以展示一个完整的模块代码例子,并分析模块代码的基本结构。
/*------------Global Module Fragment ------------*/
module;
#include "util.hpp" //在模块代码中包含头文件
/*-------------Module Declaration----------------*/
export module http.client; // 本模块的名字叫http.client
/*-------------Import Declaration----------------*/
import std; // 导入其他模块
import asio;
export import cppjson;
import openssl;
/*------------------用户代码----------------------*/
namespace http
{
namespace detail
{
class helper // 无export前缀,不会暴露给外部用户
{
//………
}
}
// Export Declaration
export enum class status
{
OK,
NotFound,
//………
}
export class client
{
tcp::socket soc;
//………
};
export int foo();
}
如上述代码所示,模块代码可以分为若干段。
1. 首先是 Global Module Fragment,全局模块代码段,所谓的全局模块,其实指的就是旧形式的无模块的代码。我们可以在这里面包含头文件,需要注意的是,这些内容只能在模块内部使用,不会自动暴露给外部用户。
2. 然后是 Module Declaration,我们在这里声明模块的名字,这份代码属于哪个模块,是哪一种模块单元。(接口单元,实现单元,模块的分区单元)
3. 接下来是 Import Declaration,我们在这里声明,这个模块将会引入哪些其他的模块代码。
4. 最后,我们可以开始写自己的代码了,可以在在这里声明或者定义一个 C++ 的类,函数,变量等。通过是否添加 export 关键字来控制这些声明是否对模块外部用户可见。
Header Unit
和上文提到的模块(Named Modules)不同,Header Unit 虽然也可以被 import,使用起来很像模块,但本质完全不同,仅仅只是可序列化的头文件。
上文提到的模块语法主要来自于微软在 2014 年的提案,然而,Google 认为这一设计无法导出宏,是一个致命缺陷,为此,Google 提出了自己的方案:Header Unit。
处于纯粹的兼容性目的,Header Unit 的效果和 #include 头文件完全相同(代码会引入宏,会被宏影响)。然而,这使得编译器只能对 Header Unit 做有限度的预处理,从而大大限制了编译器的加速空间。
import <iostream>;
// 和#include <iostream>的效果完全相同。
// 会引入宏,iostream中的代码也可能会被宏影响
int main()
{
std::cout<<"Hello world"<<std::endl;
}小结
这里总结一下模块单元的类别:
1. Interface Unit:一个模块只能有一个 Interface,在这里声明哪些符号暴露给外部用户
2. Implementation Unit:一个模块可以有多个 Implementation Unit,可以这里实现代码。
3. Partition Unit:一个主模块可以包含多个分区单元,分区单元不是独立的,无法单独导出给模块的外部用户使用,是主模块的一部分。需要注意的是,分区单元内部也可以划分接口单元和实现单元,这两者是正交的(因此有 2*2=4 种情况)
4. Header Unit:特殊的一个单元,本质上不是模块,而是可序列化的头文件。
模块化工程
模块化工程带来了许多变化:
1. 模块化工程具有和传统头文件不同的组织架构。
2. 各模块之间具有依赖关系,这要求构建工具链能够正确的分析各个模块之间的依赖关系,得到正确的构建顺序。
3. 对头文件的兼容与改造:一方面,C++ 具有大量的基于头文件的历史代码,我们希望以尽可能小的代价将其模块化。另外一方面,我们也希望改造后的代码能够同时兼容头文件和模块两种架构模式,方便平滑过渡。
模块化项目的组织与依赖关系
传统 C++ 工程架构
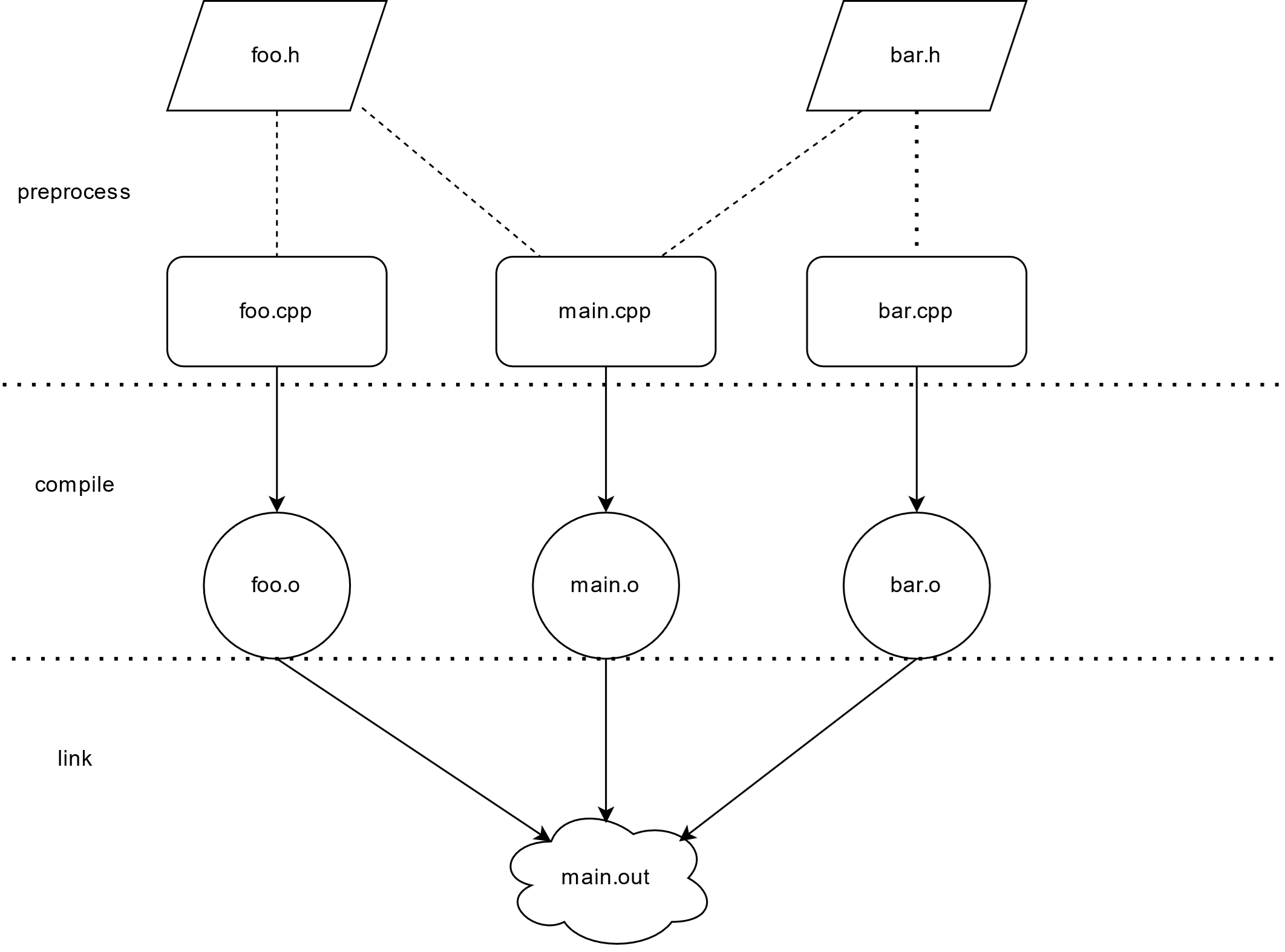
上图展示了一个传统的 C++ 工程架构,各个翻译单元(*.cpp)在编译时完全独立,互不影响。头文件被多次重复包含并编译。
由于 main.cpp 使用到了foo 和 bar 中的内容,因此它会包含 foo 和 bar 的头文件。尽管如此,每份 cpp 文件在编译的时候依然互不干涉,每个单元在编译的时候互相之间是没有依赖关系的,可以简单直接的并行编译。
基于模块的 C++ 工程架构
然而,模块代码之间却存在依赖关系,一个翻译单元需要依赖其他翻译单元的编译结果。
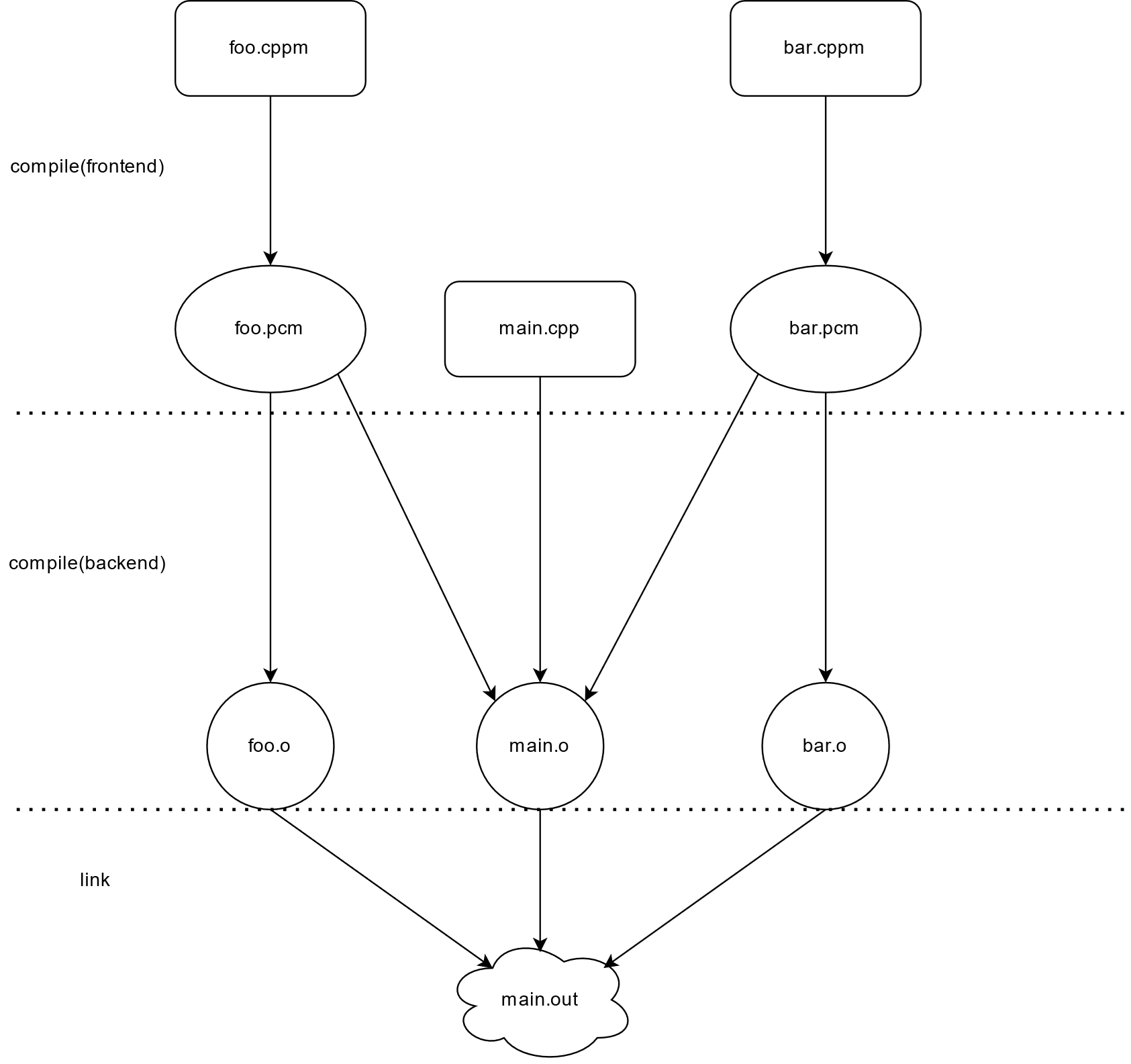
如上图所示,我们将原来使用头文件的工程改成了基于模块的工程。
由于 main.cpp 使用到了foo 和 bar 中的模块内容,每个模块需要预先编译而不能直接包含,因此,我们要先编译 foo 模块和 bar 模块,完成编译器前端处理以后,才能开始编译 main.cpp。这算是引入模块以后 C++ 工程最大的变化,各代码单元之间出现了依赖关系。
Module Wrapper
Module Wrapper 是一类特殊的技巧,其目的在于通过一个简单的模块封装层,将旧式的头文件代码转换为标准的 C++ 模块文件,从而达到兼容两者的目的。
export using declaration
第一种技巧是使用 export using declaration,我们可以快速将已有的头文件封装到模块中,不影响旧代码。
// iostream.cppm
module;
#include<iostream>
export module iostream;
namespace std {
export using std::cin;
export using std::cout;
export using std::endl;
}
// main.cpp
import iostream;
int main() {
std::cout<<"Hello Module Wrapper"<<std::endl;
}在上面的代码中,通过在 global module fragment 中包含标准库头文件,再使用 export using declaration 将这些声明导,这样,我们就制作了一个简单的标准库模块。
通过这个技巧,大家可以在不修改头文件的情况下,通过引入一个简单的中间层,把旧有的头文件代码封装到模块。实际上很多模块化标准库都是这样实现的,例如 async_simple 库中就使用该技巧简单的封装了一个标准库模块实现。
export extern c++
接下来我们介绍另外一种封装的方法,通过 export extern c++ 和模块控制宏,我们可以一口气导出头文件中所有的符号,不需要手动枚举这些声明,并兼容头文件和模块两种写法。例如 fmt 库就采用了这种方式来同时兼容头文件和模块。
// hello.hpp
#ifdef HELLO_USE_MODULE // 通过这个宏来控制是否启用模块
import std;
#else
#include<iostream>
#include<vector>
#endif
void hello() {
// ...
}
// hello.cppm
module;
export module hello;
export extern "C++" {
#define HELLO_USE_MODULE
#include<hello.hpp>
}
首先我们修改原来的头文件,在 hello.hpp 中,通过 HELLO_USE_MODULE 这个控制宏,来控制是使用模块还是头文件。
接下来,我们在 hello 模块的接口文件中,通过使用 export extern c++ 语法,并在代码段中包含对应的头文件,并启用对应的宏,就可以将整个 hello.hpp 中的代码包含在模块中,导出给用户使用。
模块重构辅助工具
可以看到,在上文介绍的模块化重构过程中,存在许多机械工作,为此,我们实验性的提供了一些自动化工具用于减少模块重构中的工作量。相关工具可能会在未来合入 Clang 主线。
它能做到:
-
自动插入宏,控制项目使用头文件还是模块。
-
自动扫描头文件之间的依赖关系(虽然不太准确)。
-
自动生成 module wrapper 文件。
详见 clang-modules-wrapper:GitHub - ChuanqiXu9/clang-modules-converter: A helper to convert a header-based C++ project to module-based one.
项目改造经验
async_simple 模块化改造
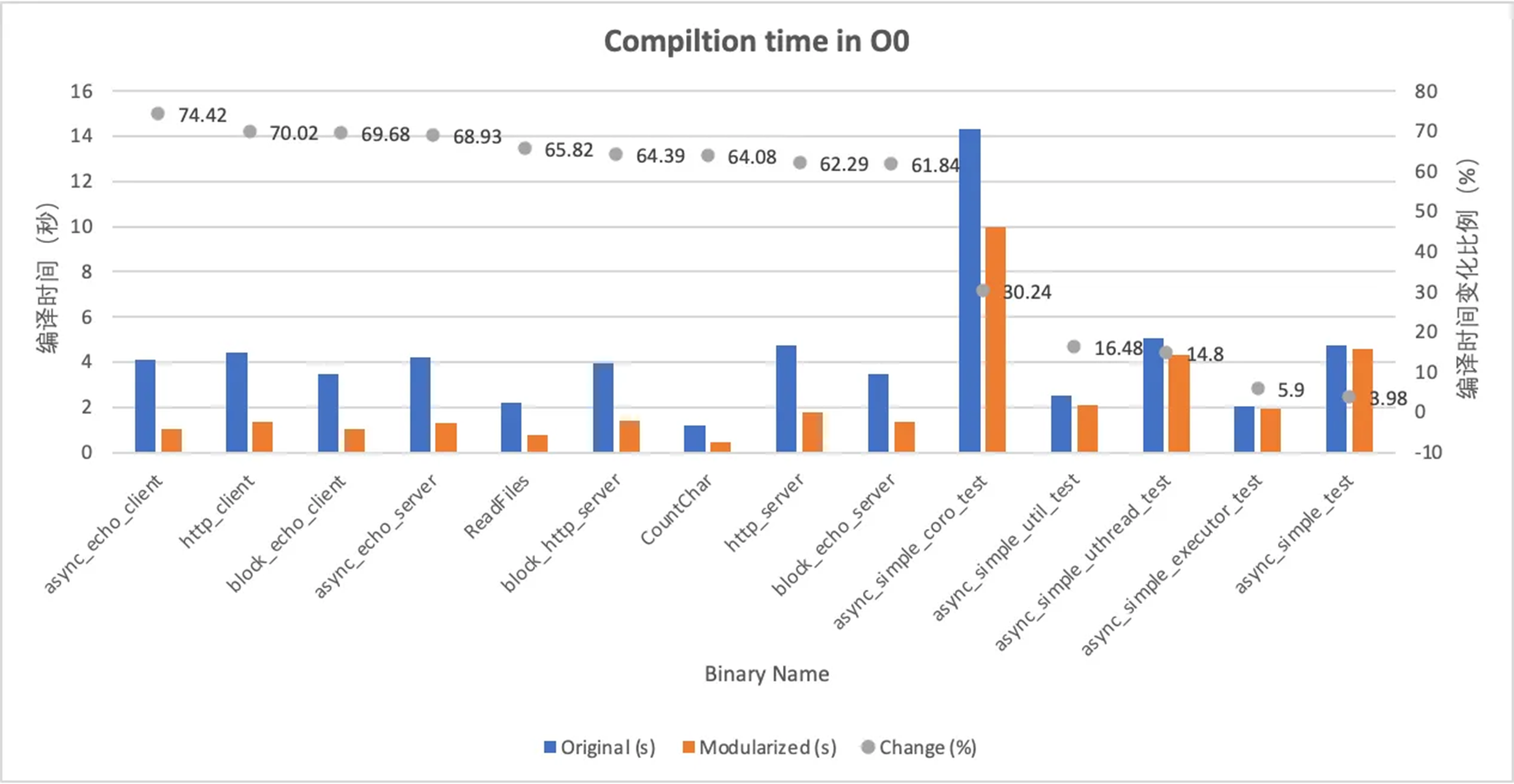
async_simple 是阿里巴巴提供的异步组件库,支持 C++20 无栈协程,C++ 有栈协程并提供了许多异步工具。
async_simple 在 2021 年末就开始使用 module 进行改造,并取得了较好的编译速度提升。
Hologres 模块化改造
阿里云计算平台 Hologres 和 Alibaba Cloud Compiler 的开发团队积极合作,自 2022 年起便开始尝试使用 Modules。
如今 Hologres 已将 Modules 作为默认开发模式并上线了基于 Modules 编译的镜像,至今已稳定运行 5 个月。
Hologres “可能”是世界上首个大规模使用 Modules 的商业项目,其改造结果如下:

Alibaba Cloud Compiler
Alibaba Cloud Compiler是阿里云打造的 C++ 编译器,可以在 Alibaba Cloud Linux 系统上使用,基于 Clang/LLVM-13 社区开源版本开发,继承开源版本支持的所有选项、参数,同时结合阿里云基础设施进行深度优化、补充特性,可以让您获得更好的 C++ 编译器体验。
Alibaba Cloud Compiler 提供了良好的 Coroutine(协程)和 Modules(模块)支持,并将这些代码积极合入到上游社区,为 Clang 对 C++ module 的支持做出了大量贡献。目前 Clang 的 C++ 模块(序列化)便是由我们的同学担 任Owner。
在阿里云 ECS 上安装 Alibaba Cloud Linux 3 系统后,我们可以通过包管理器安装 ACC 编译器:
sudo yum install -y alibaba-cloud-compiler
更多信息请见说明文档:安装并使用Alibaba Cloud Compiler构建高性能的C++应用_Alibaba Cloud Linux(Alinux)-阿里云帮助中心
代码实操:Workshop
本文共有 5 个编程任务,若您对实操部分感兴趣,小编建议大家阅读完本文即可实操。其中,WorkShop 1 和 WorkShop 2 建议您现在就可以完成,WorkShop 3 和 WorkShop 4 建议您仔细阅读“模块语法简介”后完成,WorkShop 5 完成需阅读“模块化工程”。
编译环境准备:
1. 对于一般用户,推荐您通过包管理器或者手动安装较高版本的 Clang 编译器(版本大于等于 15)。对于阿里云 ECS 用户,推荐您使用 Alibaba Cloud Linux 3 系统,并通过 yum install -y alibaba-cloud-compiler 安装 Alibaba Cloud Compiler 编译器。
2. 安装 Xmake 构建工具。请见:https://xmake.io/#/getting_started
3. 从 github 上下载 workshop 的操作指引,代码和答案解析详见代码仓库地址:GitHub - poor-circle/workshop
WorkShop 1:GoodBye Head File,链接见下:https://github.com/poor-circle/workshop/blob/master/work1/任务说明.md
WorkShop 2:Hello world,C++modules,链接见下:https://github.com/poor-circle/workshop/blob/master/work2/任务说明.md
WorkShop 3:编写单个模块,链接见下:https://github.com/poor-circle/workshop/blob/master/work3/任务说明.md
WorkShop 4:编写多模块单元链接,链接见下:https://github.com/poor-circle/workshop/blob/master/work4/任务说明.md
WorkShop 5:将传统的头文件项目转换为模块,链接见下:https://github.com/poor-circle/workshop/blob/master/work5/任务说明.md
2024 龙蜥大会上,作者受邀参加分享技术 WorkShop,现场带领大家实操,在 Anolis OS 上使用 Alibaba Cloud Compiler,将一个传统的 C++ 项目改造为 modules 的项目,体验 modules 的便利和优势,不仅仅是告别 include 头文件,还会带来编译速度的提升。
回放链接:告别头文件!C++ Modules 实战解析 - OpenAnolis龙蜥操作系统开源社区
—— 完 ——

欢迎加入龙蜥社区,参与开源活动即刻有好礼相送!
更多推荐


 24
24 0
0- 0



 已为社区贡献527条内容
已为社区贡献527条内容

所有评论(0)